La arquitectura de sistemas de bases de datos de tres esquemas fue aprobado por la ANSI-SPARC (American National Standard Institute - Standards Planning and Requirements Committee) en 1975 como ayuda para conseguir la separación entre los programas de aplicación y los datos, el manejo de múltiples vistas por parte de los usuarios y el uso de un catálogo para almacenar el esquema de la base de datos.
La arquitectura de un sistema de base de datos está influenciada en gran medida por el sistema informático subyacente en el que se ejecuta el sistema de base de datos. En la arquitectura de un sistema de base de datos se reflejan aspectos como la conexión de red, el paralelismo y la distribución.
• La conexión de red: de varias computadoras permite que algunas tareas se ejecuten en un sistema servidor y que otras se ejecuten en los sistemas clientes. Esta división de trabajo ha conducido al desarrollo de sistemas de base de datos cliente-servidor.
• El procesamiento paralelo: dentro de una computadora permite acelerar las actitudes del sistema de base de datos, proporcionando a las transacciones una respuesta más rápida, así como la capacidad de ejecutar más transacciones por segundo.
• La distribución de datos: A través de las distintas sedes o departamentos de una organización permite que estos datos residan donde han sido generados o donde son más necesarios, pero continuar siendo accesibles desde otros lugares o departamentos diferentes
- Nivel interno o nivel fisico: Es el nivel mas najo de abstraccion, tiene un esquema interno que describe la estructura física de almacenamiento de base de datos. Emplea un modelo físico de datos y los únicos datos que existen están realmente en este nivel. En el nivel físico se describen en detalle las estructuras de datos complejas de bajo nivel.
- Nivel conceptual: Es el siguiente nivel más alto de abstracción, se describe cuáles son los datos reales que están almacenados en la base de datos y qué relaciones existen entre los datos,tiene esquema conceptual. Describe la estructura de toda la base de datos para una comunidad de usuarios. Oculta los detalles físicos de almacenamiento y trabaja con elementos lógicos como entidades, atributos y relaciones.
- Nivel externo o de vistas: Es el siguiente nivel más alto de abstracción describe que datos se almacenan en la base de datos y que relaciones existen entre esos datos, tiene varios esquemas externos o vistas de usuario. Cada esquema describe la visión que tiene de la base de datos a un grupo de usuarios, ocultando el resto. La base de datos completa se describe así en términos de un número pequeño de estructuras relativamente simples en el nivel físico, los usuarios del nivel lógico no necesitan preocuparse de esta complejidad. Los administradores de base de datos, que deben decidir la información que se mantiene en la base de datos, usan el nivel lógico de abstracción.

El objetivo de la arquitectura de tres niveles es el de separar los programas de aplicación de la base de datos física.
La mayoría de los SGBD no distinguen del todo los tres niveles. Algunos incluyen detalles del nivel físico en el esquema conceptual. En casi todos los SGBD que se manejan vistas de usuario, los esquemas externos se especifican con el mismo modelo de datos que describe la información a nivel conceptual, aunque en algunos se pueden utilizar diferentes modelos de datos en los niveles conceptual y externo.
Hay que destacar que los tres esquemas no son más que descripciones de los mismos datos pero con distintos niveles de abstracción. Los únicos datos que existen realmente están a nivel físico, almacenados en un dispositivo como puede ser un disco. En un SGBD basado en la arquitectura de tres niveles, cada grupo de usuarios hace referencia exclusivamente a su propio esquema externo. Por lo tanto, el SGBD debe transformar cualquier petición expresada en términos de un esquema externo a una petición expresada en términos del esquema conceptual, y luego, a una petición en el esquema interno, que se procesará sobre la base de datos almacenada. Si la petición es de una obtención (consulta) de datos, será preciso modificar el formato de la información extraída de la base de datos almacenada, para que coincida con la vista externa del usuario. El proceso de transformar peticiones y resultados de un nivel a otro se denomina correspondencia o transformación. Estas correspondencias pueden requerir bastante tiempo, por lo que algunos SGBD no cuentan con vistas externas.
La arquitectura de tres niveles es útil para explicar el concepto de independencia de datos que podemos definir como la capacidad para modificar el esquema en un nivel del sistema sin tener que modificar el esquema del nivel inmediato superior.
Se pueden definir dos tipos de independencia de datos:
- La independencia lógica es la capacidad de modificar el esquema conceptual sin tener que alterar los esquemas externos ni los programas de aplicación. Se puede modificar el esquema conceptual para ampliar la base de datos o para reducirla. Si, por ejemplo, se reduce la base de datos eliminando una entidad, los esquemas externos que no se refieran a ella no deberán verse afectados.
- La independencia física es la capacidad de modificar el esquema interno sin tener que alterar el esquema conceptual (o los externos). Por ejemplo, puede ser necesario reorganizar ciertos ficheros físicos con el fin de mejorar el rendimiento de las operaciones de consulta o de actualización de datos. Dado que la independencia física se refiere sólo a la separación entre las aplicaciones y las estructuras físicas de almacenamiento, es más fácil de conseguir que la independencia lógica.
En los SGBD que tienen la arquitectura de varios niveles es necesario ampliar el catálogo o diccionario, de modo que incluya información sobre cómo establecer la correspondencia entre las peticiones de los usuarios y los datos, entre los diversos niveles. El SGBD utiliza una serie de procedimientos adicionales para realizar estas correspondencias haciendo referencia a la información de correspondencia que se encuentra en el catálogo. La independencia de datos se consigue porque al modificarse el esquema en algún nivel, el esquema del nivel inmediato superior permanece sin cambios, sólo se modifica la correspondencia entre los dos niveles. No es preciso modificar los programas de aplicación que hacen referencia al esquema del nivel superior.
Por lo tanto, la arquitectura de tres niveles puede facilitar la obtención de la verdadera independencia de datos, tanto física como lógica. Sin embargo, los dos niveles de correspondencia implican un gasto extra durante la ejecución de una consulta o de un programa, lo cual reduce la eficiencia del SGBD. Es por esto que muy pocos SGBD han implementado esta arquitectura completa.
TIPOS DE ARQUITECTURA CLIENTE-SERVIDOR
ARQUITECTURA DE 2 CAPAS:
La arquitectura cliente/ servidor tradicional es una solución de 2 capas. La arquitectura de 2 capas consta de tres componentes distribuidos en dos capas: cliente (solicitante de servicios) y servidor (proveedor de servicios). Los tres componentes son:
- Interfaz de usuario.
- Gestión del procesamiento.
- Gestión de la base de datos.
Hay 2 tipos de arquitecturas cliente servidor de dos capas:
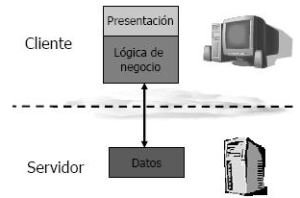
- Clientes obesos (thick clients): La mayor parte de la lógica de la aplicación (gestión del procesamiento) reside junto a la lógica de la presentación (interfaz de usuario) en el cliente, con la porción de acceso a datos en el servidor.
- Clientes delgados (thin clients): solo la lógica de la presentación reside en el cliente, con el acceso a datos y la mayoría de la lógica de la aplicación en el servidor.
Es posible que un servidor funcione como cliente de otro servidor. Esto es conocido como diseño de dos capas encadenado.
Limitaciones:
- El número usuarios máximo es de 100. Más allá de este número de usuarios se excede la capacidad de procesamiento.
- No hay independencia entre la interfaz de usuario y los tratamientos, lo que hace delicada la evolución de las aplicaciones.
- Dificultad de relocalizar las capas de tratamiento consumidoras de cálculo.
- Reutilización delicada del programa desarrollado bajo esta arquitectura.
ARQUITECTURA DE 3 CAPAS:
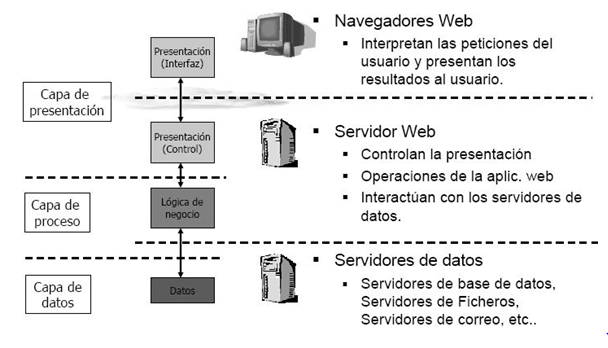
La arquitectura de 3 capas surgió para superar las limitaciones de la arquitectura de 2 capas. La tercera capa (servidor intermedio) está entre el interfaz de usuario (cliente) y el gestor de datos (servidor). La capa intermedia proporciona gestión del procesamiento y en ella se ejecutan las reglas y lógica de procesamiento. Permite cientos de usuarios (en comparación con sólo 100 usuarios de la arquitectura de 2 capas). La arquitectura de 3 capas es usada cuando se necesita un diseño cliente / servidor que proporcione, en comparación con la arquitectura de 2 capas, incrementar el rendimiento, flexibilidad, mantenibilidad, reusabilidad y escalabilidad mientras se esconde la complejidad del procesamiento distribuido al usuario.
Limitaciones:
Construir una arquitectura de 3 capas es una tarea complicada. Las herramientas de programación que soportan el diseño de arquitecturas de 3 capas no proporcionan todos los servicios deseados que se necesitan para soportar un ambiente de computación distribuida. Un problema potencial en el diseño de arquitecturas de 3 capas es que la separación de la interfaz gráfica de usuario, la lógica de gestión de procesamiento y la lógica de datos no es siempre obvia. Algunas lógicas de procesamiento de transacciones pueden aparecer en las 3 capas. La ubicación de una función particular en una capa u otra debería basarse en criterios como los siguientes:
- Facilidad de desarrollo y comprobación.
- Facilidad de administración.
- Escalabilidad de los servidores.
- Funcionamiento (incluyendo procesamiento y carga de la red).
REFERENCIAS:
- http://www.monografias.com/trabajos37/arquitectura-de-sistemas/arquitectura-de-sistemas.shtml#ixzz3eCETYrlk
- https://programacionwebisc.wordpress.com/2-1-arquitectura-de-las-aplicaciones-web/
- https://docs.google.com/document/d/1WSWPlIGuT0Acth7mnh5-MxfSjXRiWNQz9gmk-lubQvQ/edit?hl=en
- http://www.desarrolloweb.com/articulos/arquitectura-base-de-datos.html
No hay comentarios:
Publicar un comentario